
Everybody writes REST APIs today. Everybody knows REST APIs are more generic, scalable and extensible than SOAP and RPC. Or do they?
Like many I started writing REST APIs the Rails way because Rails provides everything you need to quickly write a beautiful REST API out of the box. Or so I thought.
After reading many articles and many more comments, I now understand that most so-called REST APIs today are not actually RESTful according to how REST was originally defined. Many proponents of “true REST APIs” now seem to prefer talking about Hypermedia APIs which is a more practical description of what they are. You’ll also hear about the HATEOAS principle, meaning Hypermedia As The Engine Of Application State, one of the constraints of the REST architectural style.
Now I don’t have a doctorate in computer science; I’m just a lowly software engineer trying to code some APIs. A big part of software engineering is making trade-offs. But you have to understand what you’re trading off.
For the rest of this post, I’m going to put on my “True REST & Hypermedia API” zealot hat. Aside from point 1 which is a summary of what some people incorrectly understand REST to be, this post reflects my (condensed) understanding of what REST/Hypermedia principles are. I also describe useful standards and practices that can help to put these principles into practice in an HTTP API.
Note that many people disagree that this is how it should be done. If you’re interested in knowing more, I’ve listed the articles I found most useful to understand the subject at the bottom of this post. The comments sections of these articles are particularly interesting as they contain descriptions of actual problems, possible solutions, and mostly thoughtful criticism.
A fair warning to those who may read on: this is a tl;dr kind of post.
{kind=link}
- REST: The Rails Way
- Hypermedia APIs
- Media Types
- The Link Header
- URI Templates
- API Workflow & Caching
- API Versioning
- Final Comments
REST: The Rails Way
This is the way most “REST APIs” I’ve seen work, as popularized notably by Ruby on Rails.
- A RESTful API consists of resources (that map directly or indirectly to your domain objects).
- Each resource or collection of resources has a documented, unique URI.
- These resources can be manipulated using HTTP verbs such as GET, POST, PUT, DELETE.
- Each resource can have many representations; a representation is selected
through content negotiation with the Accept header (e.g.
application/json,application/xml) or a suffix (e.g.person.json,person.xml).
In a nutshell, we’re exposing domain objects through HTTP with CRUD operations (and other custom operations, generally using POST), in some generic format like JSON.

This is the point where you may want to stop reading if you don’t want this conception of a REST API to be eviscerated and transmogrified.
Hypermedia APIs
Shockingly, there are critical properties missing for this to be a true RESTful API. Some of the above properties are even incompatible with REST principles. Was I lied to?
“REST APIs must be hypertext-driven,” wrote Roy Fielding in a rant against RPC blasphemers. What does he mean by that? And what’s up with this hyper stuff about hyperlinks and hypermedia? Why should I go through all this trouble anyway?
One word: the Web.
When you want to browse a website, there are basically two things you need to know: the root URI, and that you can follow links to new information. This is the simple but powerful concept of hyperlinks that has made the web so successful.
From a technical point of view when getting a web page, the client is getting a
representation of a resource in the text/html Internet Media
Type (formerly known as MIME
Type); this media type defines the behavior of links. The knowledge of the root
URI and the media type is sufficient to drive the interaction. Even if the other
URIs of the website change, they can be reached again from the root URI through
links.
Hypermedia APIs are based on the same principle.
A REST API should be entered with no prior knowledge beyond the initial URI (bookmark) and set of standardized media types that are appropriate for the intended audience (i.e., expected to be understood by any client that might use the API).
— Roy T. Fielding, REST APIs must be hypertext-driven
Contrary to the previous notion of REST, there should be:
- No fixed URIs (aside from the root).
- No fixed resource names or hierarchies.
The goal is not to get predefined resources at specific URIs; it is to follow hyperlinks to obtain representations of resources, wherever and whatever those resources might be.
What you should spend time defining in a Hypermedia API are the media types used for representing resources; they define link relations to other resources through hyperlinks. The interaction from state to state in your application (REpresentational State Transfer), is driven by the media types and hyperlinks, hence Hypermedia As The Engine Of Application State.
Media Types
So what is this *media type of which you speak? Surely we’re going to use JSON for our API… right?*
Almost. The problem is that application/json is not a hypermedia because it’s
not aware of links. There’s nothing in the JSON specification that tells a
client that this person_uri property you’re using is actually a link. There
are advantages to using a hyperlink-aware media type instead of plain JSON.
I’m not an expert (yet), but I’ll outline the two solutions I’ve most read about: Hypertext Application Language and custom media types.
Hypertext Application Language (HAL)
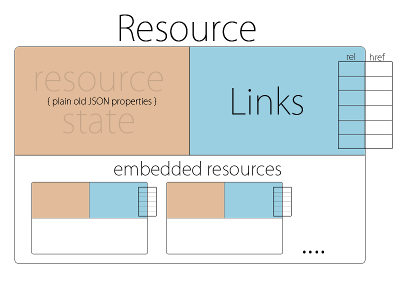
HAL is a generic JSON/XML media type for representing resources and their relations with hyperlinks.
Let’s jump right into it. The following example document represents a list of orders:
{
"currentlyProcessing": 14,
"shippedToday": 20,
"_links": {
"self": { "href": "/orders" },
"next": { "href": "/orders?page=2" },
"find": { "href": "/orders{?id}", "templated": true }
},
"_embedded": {
"orders": [
{
"_links": {
"self": { "href": "/orders/123" },
"basket": { "href": "/baskets/98712" },
"customer": { "href": "/customers/7809" }
},
"total": 30.00,
"currency": "USD",
"status": "shipped",
},
{
"_links": {
"self": { "href": "/orders/124" },
"basket": { "href": "/baskets/97213" },
"customer": { "href": "/customers/12369" }
},
"total": 20.00,
"currency": "USD",
"status": "processing"
}
]
}
}
Let’s break it down. First we have the properties of the list itself:
{
"currentlyProcessing": 14,
"shippedToday": 20,
Nothing special here. The next part is more interesting:
"_links": {
"self": { "href": "/orders" },
"next": { "href": "/orders?page=2" },
"find": { "href": "/orders{?id}", "templated": true }
}
In the JSON version of HAL, the reserved _links property indicates how to get
to related resources with hyperlinks. The keys in this map represent the rel
or relation property of the link (the same you would find in an HTML link:
<link rel="stylesheet" ...>). In this case, we have the self relation which
is itself, the next relation which indicates where to get the next page of
orders, and a find relation that can be used to find a specific order.
The last part of the document under the reserved _embedded property contains
embedded objects, which are also representations of resources with links. You
can have multiple lists of embedded objects; here there is just one under
orders:
"_embedded": {
"orders": [
{
"_links": {
"self": { "href": "/orders/123" },
"basket": { "href": "/baskets/98712" },
"customer": { "href": "/customers/7809" }
},
"total": 30.00,
"currency": "USD",
"status": "shipped",
},
]
}
The goal of HAL is to provide a standardized media type that defines how to handle hyperlinks and embedded resources. That way you don’t have to use linkless JSON/XML or develop your own media type (we’ll talk about that one later). If you use HAL, you can focus on describing the link relations that drive your application.
Since HAL is a standard, there are libraries that can help parse and generate it (you’ll find a list on the specification page). There are even HAL browsers that can automatically discover HAL APIs. You can easily find live examples with Google.
Link Relation Types
The relation property of a link in HAL (self, next, etc) is defined in Web
Linking (RFC 5988). In a nutshell, there
are two kinds of relations: Registered Relation Types and Extension
Relation Types.
Registered relation types such as self, next, previous, related are officially listed by IANA and have a specific meaning. You can use them as long as you respect their semantics.
"_links": {
"self": { "href": "/orders" },
"next": { "href": "/orders?page=2" }
}
You will of course need other relation types that are specific to your domain
model, such as a customer link in the full document example you saw earlier.
This is what extension relation types are for. According to the RFC, extension
types should be URIs that uniquely identify the relation type. For example:
"_links": {
"http://my-api.com/media/orders": {
"href": "/orders"
},
"http://my-api.com/media/orders/next": {
"href": "/orders?page=2"
}
}
These URIs may point to a resource that describes the semantics of the relation type, such as a documentation page or a PDF on your website. If you don’t want to use full URIs as relation keys, you have to make sure that they can be expanded to URIs, by using for example the CURIE Syntax:
"_links": {
"curies": [
{
"name": "ex",
"href": "http://my-api.com/media/"
}
],
"ex:orders": { "href": "/orders" },
"ex:orders/next": { "href": "/orders?page=2" }
}
That’s it for HAL.
Custom Media Types

Media types describe the representations of the resources that can be used with your API, including links to other resources. There may be multiple representations of a same resource described by different media types.
You can define your own media types to represent your resources as well as the links between them. What a media type should be, how to name and how to register it is defined in Media Type Specifications and Registration Procedures (RFC 6838). Official registration may not be necessary depending on who is going to use your API, but it’s useful if you’re hoping to create a shared standard (which could more easily be used by automated agents).
I won’t go too much into details about this RFC but I’ll give you a real-world
example: GitHub uses media types for its
API. For example, you can use the
application/vnd.github.beta.text+json media type to retrieve a comment’s body.
Let’s break that down:
-
applicationis the top-level type; the application type is for data that does not fit under other top-level media types such as text or audio, particularly data to be consumed by some type of application program. -
vndis the prefix for the vendor tree, reserved for media types of publicly available products. -
githubis the name of this particular media type. -
betais a parameter that GitHub uses to indicate the version of the API (can also bev3). -
textis another parameter to indicate the desired representation, in this case plain text. -
+jsonat the end indicates the underlying structure of the media type (the responses of their API are always wrapped in JSON).
Check out the RFC if you want to know how to build your media type. In this case, the the response might look something like this (partial headers):
HTTP/1.1 200 OK
Server: nginx
Date: Fri, 12 Oct 2012 23:33:14 GMT
Content-Type: application/vnd.github.beta.text+json; charset=utf-8
{
"body_text": "This commit is awesome."
}
This has no links though. For a better comparison with previous examples,
imagine a media type vnd.myapi.orders+json representing a list of orders like
the one in the HAL example. The response might look like this:
HTTP/1.1 200 OK
Server: nginx
Date: Fri, 12 Oct 2012 23:33:14 GMT
Content-Type: application/vnd.myapi.orders+json; charset=utf-8
{
"uri": "/orders",
"next_uri": "/orders?page=2",
"find_uri": "/orders{?id}",
"currentlyProcessing": 14,
"shippedToday": 20,
"orders": [
{
"uri": "/orders/123",
"basket_uri": "/baskets/98712",
"customer_uri": "/customers/7809",
"total": 30.00,
"currency": "USD",
"status": "shipped"
}
]
}
Instead of having a standard syntax for hyperlinks like HAL, the custom media
type must define the link relations. The documentation page for this media type
might for example indicate that the uri property is a link to the resource
itself, whereas basket_uri is a link to a resource which can be represented
with another media type such as vnd.myapi.basket+json. For HTTP APIs, the
media type may also describes what HTTP verbs are applicable and the associated
behavior.
All the media types used by your API must be part of the contract with the API clients, but the URI structure is allowed to change independently, and new representations can be easily be added to existing resources.
The Link Header
Whether you choose HAL, custom media types or plain JSON, the HTTP Link Header can also be used to provide hyperlinks with your resource representations. A link header looks like this:
Link: </orders?page=2>; rel="next"; title="Next page of orders"
You can provide multiple link headers, or multiple links in one header:
Link: </orders?page=1>; rel="prev", </orders?page=2>; rel="next"
This can be a quick way to add hyperlinks to your API if you don’t use a hypermedia format or cannot immediately define a custom media type.
Note that Web Linking (RFC 5988) defines that extension relation types (your custom business types) in link headers are required to be absolute URIs, for example:
Link: </baskets/98712>; rel="http://my-api.com/media/basket";
title="The basket containing the ordered items"
URI Templates
URI Template (RFC 6570) defines a useful format to describe a range of URIs through variable expansion. You can use it to provide more information about URI parameters in your API.
As a quick example taken from the RFC, imagine that you have these parameterized URIs:
http://example.com/~fred/
http://example.com/~mark/
http://example.com/dictionary/c/cat
http://example.com/dictionary/d/dog
http://example.com/search?q=cat&lang=en
http://example.com/search?q=chien&lang=fr
You can express them as URI templates:
http://example.com/~{username}/
http://example.com/dictionary/{term:1}/{term}
http://example.com/search{?q,lang}
The RFC describes the supported expression expansions. I encourage you to read and use it.
API Workflow & Caching
Now you will surely ask, as many have before you:
Do you really expect me to go through all those link relations to get at my resource? Can’t I just go to the URI directly?
— Angry Developer, Somewhere on the internet
No, you can’t. Not if you want to follow the principles of REST and Hypermedia. You’re supposed to follow these links in order to reduce the client/server coupling and allow the resources and URI structure to evolve independently. The URIs should not even be in your documentation (aside from the root).
Let’s take the previous example of the list of orders. Assume that you have an order ID and want to get a JSON representation of that order. Also assume that the only knowledge you have is the root of the API and the custom media types it uses.
You must first find the orders resource from the root:
$> curl -H 'Accept: application/vnd.myapi+json' /
HTTP/1.1 200 OK
Content-Type: application/vnd.myapi+json; charset=utf-8
{
"uri": "/",
"docs_uri": "/docs",
"orders_uri": "/orders"
}
This representation of the root resource is described by a custom media type.
You would know from the documentation of this application/vnd.myapi+json media
type that the orders_uri property is a link to the orders resource you need,
and that it has a representation in some other media type like
application/vnd.myapi.orders+json. Let’s GET that:
$> curl \
-H 'Accept: application/vnd.myapi.orders+json' \
/orders
HTTP/1.1 200 OK
Content-Type: application/vnd.myapi.orders+json; charset=utf-8
{
"uri": "/orders",
"next_uri": "/orders?page=2",
"find_uri": "/orders{?id}",
"currentlyProcessing": 14,
"shippedToday": 20,
"orders": [
...
]
}
Again, from the media type you would know that you can find the resource you’re
looking for through the templated find_uri link:
$> curl -L \
-H 'Accept: application/vnd.myapi.order+json' \
/orders?id=425
HTTP/1.1 302 Found
Location: http://my-api.com/orders/123
HTTP/1.1 200 OK
Content-Type: application/vnd.myapi.order+json; charset=utf-8
{
"uri": "/orders/123",
"basket_uri": "/baskets/98712",
"customer_uri": "/customers/7809",
"total": 30.00,
"currency": "USD",
"status": "shipped"
}
In this example, that’s three calls and a redirect to get to the order resource you were looking for.
“Unacceptable!” you say? Well that’s how Hypermedia APIs work.
However, this example uses many steps on purpose to illustrate hyperlinks. You could add a link to find orders directly in the representation of the root resource, saving one call.
You can also build on top of standard HTTP caching mechanisms. All responses may
contain cache control headers like Cache-Control, Expires,
Last-Modified-Since, ETag. Clients may then cache the response for some
time, or send headers like If-Modified-Since and If-None-Match and get back
an HTTP 304 Not Modified response if the resources (and their URIs) have not
changed.
In most cases calls will be much faster with caching and less data will be transferred. You don’t necessarily have to do it yourself; some well-behaved HTTP tools can handle it for you. For example when using jQuery, data will be automatically cached by the browser if applicable.
HTTP caching is described in Hypertext Transfer Protocol – HTTP/1.1 (RFC 2616), notably Section 13 - Caching in HTTP. I strongly suggest you read up on this if you haven’t already.
API Versioning
Over time your API will inevitably change: new features will be added; existing features will be changed; old features will be removed. How can backward- and forward-compatibility with API clients be maintained?
There is heated debate over how to handle this issue in REST APIs. I’ve mostly seen four options that I’ll describe here.
URI Versioning
This consists of adding a version number to all your URIs. You change the version number when resources change in backward-incompatible ways.
http://my-api.com/v1/orders
http://my-api.com/v2/orders
Theoretically this is not RESTful. There’s no reason to change the URI of a resource even if it changes in backward-incompatible ways, as long as it’s still conceptually the same resource. Media type versioning can handle this as I’ll describe later. However, I’ll allow this digression because it seems to be the most used solution out there.
Versioning the URI is a straightforward solution to support multiple versions of an API at the same time. As long as your backend can handle it (thinking mostly of complexity here), releasing a version 2 under different URIs ensures that version 1 clients will continue to function.
In most cases, it is recommended that you only use a major version number. A scheme like semantic versioning would be overkill for an API. Additions and backward-compatible changes should not increase the version number.
Most API developers have chosen the URI versioning solution because it is simple to understand and to implement.
No Versioning
I’ve seen people writing that you should not version an API because it hinders its evolution. If you have changes so big that they’re completely backward-incompatible, they should be new resources or new links in resource representations. I haven’t seen any example of this but I wonder where that might lead after many resources and links have been added. Probably a big mess.
Link Versioning
A solution similar to new links is to version links within a resource.
{
"v1_basket_uri": "http://my-api.com/baskets/123",
"v2_basket_uri": "http://my-api.com/orders/234/basket"
}
That way it’s still possible to have multiple behaviors of the same resources in parallel without changing the original URIs. I also haven’t seen actual examples of this but I’ve seen it discussed mostly in the context of HAL.
Media Type Versioning
If a resource has backward-incompatible changes that cannot be supported by its
current representation, then it should have a new representation described by a
new media type. For example, you might go from
application/vnd.myapi.basket.v1+json to
application/vnd.myapi.basket.v2+json. No URIs need to be changed; the new
version is essentially just another representation of the same resource,
documented separately. Different representations can be used by different
clients at the same time.
This is I think the most elegant way to version resources. On the whole, most Hypermedia articles I’ve read that are not about HAL prefer this solution. It seems to best fit REST and Hypermedia principles.
It does require the client and server to be aware of and correctly interpret media types, which is the goal of a Hypermedia API.
Final Comments

Let me take the zealot hat off.
Hypermedia APIs are not a silver bullet. Clients must still know your media types and link relations. In a perfect world where all API developers standardize and share their media types then sure, automated agents may be able to browse them. But in the real world most APIs are going to have their own custom media types. Even with HAL the links are going to be specific to your application or business.
Hypermedia APIs also place a greater burden on their clients: the API must be browsed through link relations instead of using hard-coded URIs, and caching should be used for maximum efficiency.
However, applying Hypermedia principles does decrease client/server coupling and promote evolution; it hides your resources and their implementation details behind representations described by media types; and it allows the URI structure to evolve independently by using hyperlinks instead of fixed resource names and hierarchies.
REST is software design on the scale of decades: every detail is intended to promote software longevity and independent evolution.
— Roy T. Fielding, REST APIs must be hypertext-driven
REST and Hypermedia principles have been carefully designed to solve the problems of the web while retaining the properties that have made it successful. If you don’t understand these principles yet, you should definitely look into it before dismissing them as academic or impractical. Once you understand, choose what is most appropriate to your needs.
I don’t think that Hypermedia APIs are much harder to implement. You just have to focus on media types and to make sure that the documentation reflects the hypertext-driven nature of the API, not the URI structure. And of course, these principles do not replace careful design of your resource representations to avoid as many changes as possible in the future.
As for me, I will develop my next APIs as Hypermedia APIs to put these principles into practice.
May your API clients never break.
Meta
- REST APIs must be hypertext-driven (Untangled, musings of Roy T. Fielding)
- REST is over (Literate Programming)
- Nobody Understands REST or HTTP (Literate Programming)
- Some People Understand REST and HTTP (Literate Programming)
- Haters gonna HATEOAS (The timeless repository)
- What the hell is a Hypermedia API, and why should I care? (2beards)
- Versioning REST Services (Informit)
- Hypermedia APIs - less hype more media, please (Speaker Deck)
- Web API Versioning Smackdown (Mnot’s Blog)
- Advantages Of (Also) Using HATEOAS in RESTful APIs (InfoQ)
- How to GET a Cup of Coffee (InfoQ)
- Honing in on HATEOAS (apigee)
- API Design: Harnessing HATEOAS, Part 1 (apigee)
- Designing Hypermedia APIs (steveklabnik@github)
- HAL+JSON Specification
- Getting hyper about hypermedia APIs (Signal vs. Noise)
- Cool URIs don’t change (W3C)
Relevant RFCs
- RFC 2616: Hypertext Transfer Protocol – HTTP/1.1
- RFC 5988: Web Linking
- RFC 6570: URI Template
- RFC 6838: Media Type Specifications and Registration Procedures
- JSON Hypertext Application Language (draft)
Architectural Styles and the Design of Network-based Software Architectures
Roy Fielding’s doctoral dissertation which first defined REST.